From data to decision in a coffee shop with two baristas
• Data → Mean → Standard deviation → Standard error → A/B comparison → z-score → Hypothesis testing → Decision
🟦 1. The Data — Customers Waiting for Coffee
Imagine you own a small coffee shop.
You have two baristas:
- 👩🍳 Anna
- 👨🍳 Ben
Every morning, customers queue up, and you start timing:
- How long each customer waits from order to drink in hand.
At this point, the data look messy:
- One customer: 18 seconds
- Another: 42 seconds
- A big order: 65 seconds
- A simple espresso: 14 seconds
You’re not doing statistics yet.
You’re just observing the world.
💬 Intuition:
Raw data is just reality recorded. It’s noisy and ugly – and that’s fine.
🟩 2. The Mean — “Typical” Wait Time
You’d like to compress all this into something like:
“How long does a customer typically wait with Anna?”
“How long with Ben?”
That’s where the mean comes in.
Suppose after timing many customers, you get:
- Anna’s average wait time: 28 seconds
- Ben’s average wait time: 31 seconds
The mean is the balancing point of all the data.
If you imagine every wait time as a weight on a number line, the mean is where the plank balances.
💡 Why the mean?
Because it’s the best single guess of “central tendency” when you care about squared error (which we’ll get to soon).
🟧 3. Standard Deviation — How Wild is the Experience?
Two baristas could have the same average, but very different consistency.
- Some days are smooth.
- Some are chaotic.
To capture this, we use standard deviation (SD).
- If Anna’s SD is 6 seconds, her wait times are tightly clustered.
- If Ben’s SD is 12 seconds, his times are more spread out.
💬 Intuition:
SD answers: “How much, on average, do individual wait times wiggle around the mean?”
🧮 Side Note: Variance and Squared Error
Variance is the average squared deviation from the mean.
Why squared?
- It ignores sign (Prevents negatives from canceling positives).
- Makes large deviations matter more
- It gives nice math: the mean is the point that minimizes the sum of squared errors.
💡 What does “the mean is the point that minimizes the sum of squared errors” actually mean?
👉 If you pick any number to represent your data, the mean is the number that gives you the smallest total squared difference from all data points.
This is an optimization statement.
Let’s break it down using developer mental models.
Imagine you have a list of numbers:
25, 30, 28, 29And you want one single value to represent them.
Let’s call that value M.
But how do you choose M?
🔧 Step 1 — Think of M as a “central” value
You want M to be close to all the values.
So you measure how far M is from each one:
distance = each value - MBut distances can be negative (e.g., 25 - 28 = -3), so we square them to make them always positive.
So we compute:
(25 - M)²
(30 - M)²
(28 - M)²
(29 - M)²And then add them up.
This gives us a score:
- Bigger score → M is a bad choice
- Smaller score → M is a good choice
🧠 Step 2 — Try different values for M
Try M = 10 → far from all numbers → huge score Try M = 100 → even worse Try M = 27 → getting closer Try M = 28 → even better Try M = 29 → also good, but slightly worse Try M = 40 → bad again
It turns out that the one single value that gives the smallest score is always the mean.
🎨 Developer-Friendly Metaphor
Think of each data point as pulling on a point M with a string.
If M is too far left → right-side numbers pull harder
If M is too far right → left-side numbers pull harder
Squaring the distances makes longer pulls much stronger
The mean is the exact point where all the pulls balance.
It’s the optimal compromise.
OK, I hope that clears it up, now…
Standard deviation is just: bringing the spread back to the original units (seconds).
🟨 4. A Crucial Shift: From Data → Estimates
Up to now, we’ve described the data itself. Now we change perspective.
Imagine repeating the same experiment:
- Today you sample 20 customers
- Tomorrow you sample another 20
- Next week, another 20
- Each time, you’ll get a slightly different mean.
So the real question becomes:
If we repeated this measurement many times, how much would our calculated mean wobble?
That difference between averages is what Standard Error measures.
Imagine throwing darts at a board.
- Standard deviation tells you how scattered the hits are.
- Standard error tells you how much your estimate of the bullseye would change if you kept playing multiple games
Intuition:
- A larger sample gives more information, so our best guess of the true mean becomes more precise.
- That’s why the uncertainty shrinks with √N.
Rule of Thumb:
- We have less uncertainty as we take more samples
- Doubling your sample cuts uncertainty by about 1/√2.
🟨 5. Standard Error — How Uncertain is Our Mean?
So far we’ve described the data (mean & standard deviation) and then how certain we are about the mean (SE). This next step uses that uncertainty to compare two means rigorously.
This is where people often get lost — so let’s slow down.
What Standard Error Is:
Standard deviation describes spread in your data.
Standard error describes spread in your estimates — that is, how much your calculated mean would vary across repeated studies.
If standard deviation is about individual variation, standard error is about estimation uncertainty.
We now know:
- The mean wait time (28s vs 31s)
- The SD (how much individual customers vary)
But here’s the deeper question:
“How uncertain am I about that average?”
If you only timed 5 customers, you’re not very sure.
If you timed 500 customers, you’re more confident.
This is what standard error (SE) measures:
Where:
- SD = standard deviation of individual wait times
- N = number of customers sampled
💬 Intuition:
SE is the uncertainty of your mean.
More data → √N grows → SE shrinks → your estimate sharpens.
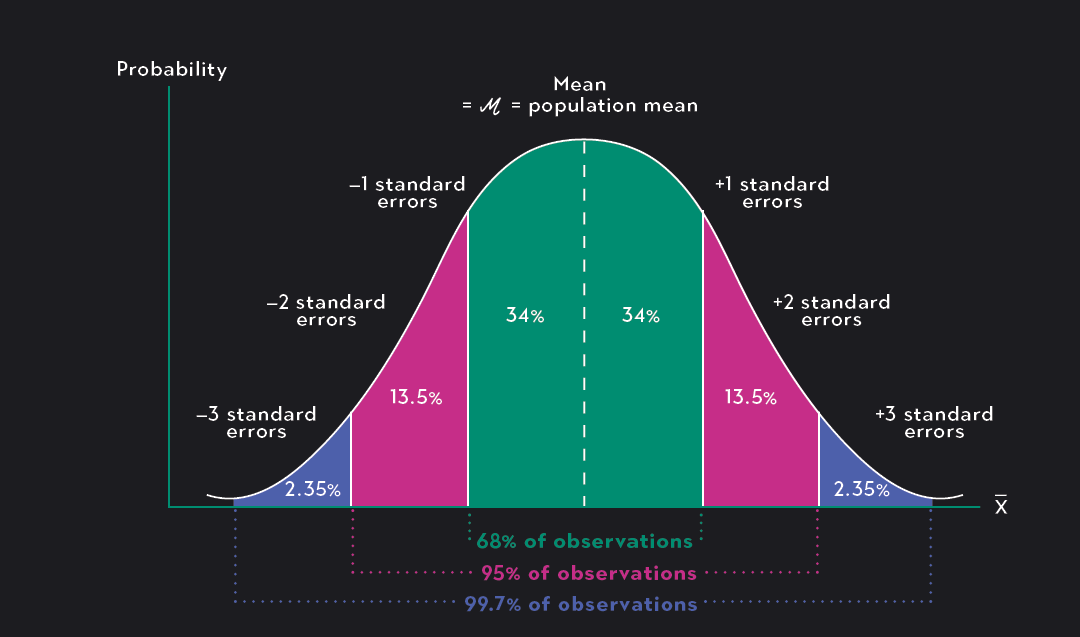
Sampling Distributions
Our objective:
Standard error tells us not just what the average is, but how confident we can be about that average — which is essential for deciding whether a difference (like between Anna and Ben) is real or just noise.
🟥 6. Comparing Anna vs Ben — A/B Logic
Now we move from describing one barista to comparing two.
We define:
Interpretation:
- If → Anna is faster (smaller wait time).
- If → Ben is faster
But δ is based on sample data — so it’s noisy too.
Every measured mean has uncertainty, so the difference does too:
We need its standard error:
This comes from the rule:
If two estimates are independent,
variance of the difference = sum of their variances.
Since SE² = variance of the estimate, their squared SEs add.
💬 Intuition:
tells us how noisy this comparison is. If SE_δ is tiny, even a small δ might be meaningful.
If SE_δ is huge, you might be seeing random fluke.
🟪 7. Z-Score — Measuring Difference in Units of Noise
Now we compress everything (the entire comparison) into a single number:
This is the z-score.
It answers:
“How many standard errors away from zero is this observed difference?”
- → no meaningful difference
- → Anna is 2 SEs faster
- → Ben is 3 SEs faster
🧮 Sidebar: Why does z follow a bell curve?
Because δ is built from averages of many independent observations.
By the Central Limit Theorem (CLT),
those averages are approximately normally distributed,
no matter what the original data looked like (within reasonable conditions).
Dividing by SE standardizes it so:
under the assumption “true δ = 0”.
🟫 8. Hypothesis Testing — Turning Evidence Into Decisions
We now have:
- A difference, δ
- Its noise level, (uncertainty)
- A standardized score, z (standardized evidence)
Hypothesis testing wraps this into a decision rule.
🧩 The game:
-
Null hypothesis (H₀):
Anna and Ben have the same true mean wait time -
Alternative (H₁):
Anna and Ben differ or even directionally: Anna is faster -
Compute:
-
Ask: Under , with , how likely is a value as extreme as ours? how probable is a z as extreme as the one we observed?
This probability is called the p-value — it tells you how surprising your observed result would be if the null hypothesis were true.
-
Decision:
- If the p-value is small (say, < 5% or 0.05), act as if the difference is real, and route more customers to the faster barista.
- If not, you don’t have enough evidence yet.
⚠️ Important:
You never get certainty.
You get a bet with a known error rate (e.g. at most 5% chance of being wrong in this specific way). You get a controlled risk of being wrong.
🧭 9. The Whole Journey
Here’s the full progression from noisy data to decision:
%3btext-align:center%3b%7d%23mermaid-0 .edgeLabel p%7bbackground-color:rgba(232%2c232%2c232%2c 0.8)%3b%7d%23mermaid-0 .edgeLabel rect%7bopacity:0.5%3bbackground-color:rgba(232%2c232%2c232%2c 0.8)%3bfill:rgba(232%2c232%2c232%2c 0.8)%3b%7d%23mermaid-0 .labelBkg%7bbackground-color:rgba(232%2c 232%2c 232%2c 0.5)%3b%7d%23mermaid-0 .cluster rect%7bfill:%23ffffde%3bstroke:%23aaaa33%3bstroke-width:1px%3b%7d%23mermaid-0 .cluster text%7bfill:%23333%3b%7d%23mermaid-0 .cluster span%7bcolor:%23333%3b%7d%23mermaid-0 div.mermaidTooltip%7bposition:absolute%3btext-align:center%3bmax-width:200px%3bpadding:2px%3bfont-family:arial%2csans-serif%3bfont-size:12px%3bbackground:hsl(80%2c 100%25%2c 96.2745098039%25)%3bborder:1px solid %23aaaa33%3bborder-radius:2px%3bpointer-events:none%3bz-index:100%3b%7d%23mermaid-0 .flowchartTitleText%7btext-anchor:middle%3bfont-size:18px%3bfill:%23333%3b%7d%23mermaid-0 rect.text%7bfill:none%3bstroke-width:0%3b%7d%23mermaid-0 .icon-shape%2c%23mermaid-0 .image-shape%7bbackground-color:rgba(232%2c232%2c232%2c 0.8)%3btext-align:center%3b%7d%23mermaid-0 .icon-shape p%2c%23mermaid-0 .image-shape p%7bbackground-color:rgba(232%2c232%2c232%2c 0.8)%3bpadding:2px%3b%7d%23mermaid-0 .icon-shape rect%2c%23mermaid-0 .image-shape rect%7bopacity:0.5%3bbackground-color:rgba(232%2c232%2c232%2c 0.8)%3bfill:rgba(232%2c232%2c232%2c 0.8)%3b%7d%23mermaid-0 .label-icon%7bdisplay:inline-block%3bheight:1em%3boverflow:visible%3bvertical-align:-0.125em%3b%7d%23mermaid-0 .node .label-icon path%7bfill:currentColor%3bstroke:revert%3bstroke-width:revert%3b%7d%23mermaid-0 :root%7b--mermaid-font-family:arial%2csans-serif%3b%7d%3c/style%3e%3cg%3e%3cmarker id='mermaid-0_flowchart-v2-pointEnd' class='marker flowchart-v2' viewBox='0 0 10 10' refX='5' refY='5' markerUnits='userSpaceOnUse' markerWidth='8' markerHeight='8' orient='auto'%3e%3cpath d='M 0 0 L 10 5 L 0 10 z' class='arrowMarkerPath' style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-0_flowchart-v2-pointStart' class='marker flowchart-v2' viewBox='0 0 10 10' refX='4.5' refY='5' markerUnits='userSpaceOnUse' markerWidth='8' markerHeight='8' orient='auto'%3e%3cpath d='M 0 5 L 10 10 L 10 0 z' class='arrowMarkerPath' style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-0_flowchart-v2-circleEnd' class='marker flowchart-v2' viewBox='0 0 10 10' refX='11' refY='5' markerUnits='userSpaceOnUse' markerWidth='11' markerHeight='11' orient='auto'%3e%3ccircle cx='5' cy='5' r='5' class='arrowMarkerPath' style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-0_flowchart-v2-circleStart' class='marker flowchart-v2' viewBox='0 0 10 10' refX='-1' refY='5' markerUnits='userSpaceOnUse' markerWidth='11' markerHeight='11' orient='auto'%3e%3ccircle cx='5' cy='5' r='5' class='arrowMarkerPath' style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-0_flowchart-v2-crossEnd' class='marker cross flowchart-v2' viewBox='0 0 11 11' refX='12' refY='5.2' markerUnits='userSpaceOnUse' markerWidth='11' markerHeight='11' orient='auto'%3e%3cpath d='M 1%2c1 l 9%2c9 M 10%2c1 l -9%2c9' class='arrowMarkerPath' style='stroke-width: 2%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cmarker id='mermaid-0_flowchart-v2-crossStart' class='marker cross flowchart-v2' viewBox='0 0 11 11' refX='-1' refY='5.2' markerUnits='userSpaceOnUse' markerWidth='11' markerHeight='11' orient='auto'%3e%3cpath d='M 1%2c1 l 9%2c9 M 10%2c1 l -9%2c9' class='arrowMarkerPath' style='stroke-width: 2%3b stroke-dasharray: 1%2c 0%3b'/%3e%3c/marker%3e%3cg class='root'%3e%3cg class='clusters'/%3e%3cg class='edgePaths'%3e%3cpath d='M138%2c62L138%2c66.167C138%2c70.333%2c138%2c78.667%2c138%2c86.333C138%2c94%2c138%2c101%2c138%2c104.5L138%2c108' id='L_A_B_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_A_B_0' data-points='W3sieCI6MTM4LCJ5Ijo2Mn0seyJ4IjoxMzgsInkiOjg3fSx7IngiOjEzOCwieSI6MTEyfV0=' marker-end='url(%23mermaid-0_flowchart-v2-pointEnd)'/%3e%3cpath d='M138%2c166L138%2c170.167C138%2c174.333%2c138%2c182.667%2c138%2c190.333C138%2c198%2c138%2c205%2c138%2c208.5L138%2c212' id='L_B_C_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_B_C_0' data-points='W3sieCI6MTM4LCJ5IjoxNjZ9LHsieCI6MTM4LCJ5IjoxOTF9LHsieCI6MTM4LCJ5IjoyMTZ9XQ==' marker-end='url(%23mermaid-0_flowchart-v2-pointEnd)'/%3e%3cpath d='M138%2c294L138%2c298.167C138%2c302.333%2c138%2c310.667%2c138%2c318.333C138%2c326%2c138%2c333%2c138%2c336.5L138%2c340' id='L_C_D_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_C_D_0' data-points='W3sieCI6MTM4LCJ5IjoyOTR9LHsieCI6MTM4LCJ5IjozMTl9LHsieCI6MTM4LCJ5IjozNDR9XQ==' marker-end='url(%23mermaid-0_flowchart-v2-pointEnd)'/%3e%3cpath d='M138%2c422L138%2c426.167C138%2c430.333%2c138%2c438.667%2c138%2c446.333C138%2c454%2c138%2c461%2c138%2c464.5L138%2c468' id='L_D_E_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_D_E_0' data-points='W3sieCI6MTM4LCJ5Ijo0MjJ9LHsieCI6MTM4LCJ5Ijo0NDd9LHsieCI6MTM4LCJ5Ijo0NzJ9XQ==' marker-end='url(%23mermaid-0_flowchart-v2-pointEnd)'/%3e%3cpath d='M138%2c550L138%2c554.167C138%2c558.333%2c138%2c566.667%2c138%2c574.333C138%2c582%2c138%2c589%2c138%2c592.5L138%2c596' id='L_E_F_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_E_F_0' data-points='W3sieCI6MTM4LCJ5Ijo1NTB9LHsieCI6MTM4LCJ5Ijo1NzV9LHsieCI6MTM4LCJ5Ijo2MDB9XQ==' marker-end='url(%23mermaid-0_flowchart-v2-pointEnd)'/%3e%3cpath d='M138%2c654L138%2c658.167C138%2c662.333%2c138%2c670.667%2c138%2c678.333C138%2c686%2c138%2c693%2c138%2c696.5L138%2c700' id='L_F_G_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_F_G_0' data-points='W3sieCI6MTM4LCJ5Ijo2NTR9LHsieCI6MTM4LCJ5Ijo2Nzl9LHsieCI6MTM4LCJ5Ijo3MDR9XQ==' marker-end='url(%23mermaid-0_flowchart-v2-pointEnd)'/%3e%3cpath d='M138%2c782L138%2c786.167C138%2c790.333%2c138%2c798.667%2c138%2c806.333C138%2c814%2c138%2c821%2c138%2c824.5L138%2c828' id='L_G_H_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_G_H_0' data-points='W3sieCI6MTM4LCJ5Ijo3ODJ9LHsieCI6MTM4LCJ5Ijo4MDd9LHsieCI6MTM4LCJ5Ijo4MzJ9XQ==' marker-end='url(%23mermaid-0_flowchart-v2-pointEnd)'/%3e%3cpath d='M138%2c910L138%2c914.167C138%2c918.333%2c138%2c926.667%2c138%2c934.333C138%2c942%2c138%2c949%2c138%2c952.5L138%2c956' id='L_H_I_0' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' style='%3b' data-edge='true' data-et='edge' data-id='L_H_I_0' data-points='W3sieCI6MTM4LCJ5Ijo5MTB9LHsieCI6MTM4LCJ5Ijo5MzV9LHsieCI6MTM4LCJ5Ijo5NjB9XQ==' marker-end='url(%23mermaid-0_flowchart-v2-pointEnd)'/%3e%3c/g%3e%3cg class='edgeLabels'%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_A_B_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_B_C_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_C_D_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_D_E_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_E_F_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_F_G_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_G_H_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg class='label' data-id='L_H_I_0' transform='translate(0%2c 0)'%3e%3cforeignObject width='0' height='0'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' class='labelBkg' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cg class='nodes'%3e%3cg class='node default' id='flowchart-A-0' transform='translate(138%2c 35)'%3e%3crect class='basic label-container' style='' x='-102.609375' y='-27' width='205.21875' height='54'/%3e%3cg class='label' style='' transform='translate(-72.609375%2c -12)'%3e%3crect/%3e%3cforeignObject width='145.21875' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eRaw Wait Time Data%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='flowchart-B-1' transform='translate(138%2c 139)'%3e%3crect class='basic label-container' style='' x='-84.6953125' y='-27' width='169.390625' height='54'/%3e%3cg class='label' style='' transform='translate(-54.6953125%2c -12)'%3e%3crect/%3e%3cforeignObject width='109.390625' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eCompute Mean%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='flowchart-C-3' transform='translate(138%2c 255)'%3e%3crect class='basic label-container' style='' x='-130' y='-39' width='260' height='78'/%3e%3cg class='label' style='' transform='translate(-100%2c -24)'%3e%3crect/%3e%3cforeignObject width='200' height='48'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table%3b white-space: break-spaces%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b width: 200px%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eCompute Standard Deviation%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='flowchart-D-5' transform='translate(138%2c 383)'%3e%3crect class='basic label-container' style='' x='-130' y='-39' width='260' height='78'/%3e%3cg class='label' style='' transform='translate(-100%2c -24)'%3e%3crect/%3e%3cforeignObject width='200' height='48'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table%3b white-space: break-spaces%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b width: 200px%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eCompute Standard Error of Mean%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='flowchart-E-7' transform='translate(138%2c 511)'%3e%3crect class='basic label-container' style='' x='-130' y='-39' width='260' height='78'/%3e%3cg class='label' style='' transform='translate(-100%2c -24)'%3e%3crect/%3e%3cforeignObject width='200' height='48'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table%3b white-space: break-spaces%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b width: 200px%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eCompare Means: delta = Anna - Ben%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='flowchart-F-9' transform='translate(138%2c 627)'%3e%3crect class='basic label-container' style='' x='-97.15625' y='-27' width='194.3125' height='54'/%3e%3cg class='label' style='' transform='translate(-67.15625%2c -12)'%3e%3crect/%3e%3cforeignObject width='134.3125' height='24'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eCompute SE_delta%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='flowchart-G-11' transform='translate(138%2c 743)'%3e%3crect class='basic label-container' style='' x='-130' y='-39' width='260' height='78'/%3e%3cg class='label' style='' transform='translate(-100%2c -24)'%3e%3crect/%3e%3cforeignObject width='200' height='48'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table%3b white-space: break-spaces%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b width: 200px%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eCompute z = delta / SE_delta%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='flowchart-H-13' transform='translate(138%2c 871)'%3e%3crect class='basic label-container' style='' x='-130' y='-39' width='260' height='78'/%3e%3cg class='label' style='' transform='translate(-100%2c -24)'%3e%3crect/%3e%3cforeignObject width='200' height='48'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table%3b white-space: break-spaces%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b width: 200px%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eEvaluate z under standard normal%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='node default' id='flowchart-I-15' transform='translate(138%2c 999)'%3e%3crect class='basic label-container' style='' x='-130' y='-39' width='260' height='78'/%3e%3cg class='label' style='' transform='translate(-100%2c -24)'%3e%3crect/%3e%3cforeignObject width='200' height='48'%3e%3cdiv xmlns='http://www.w3.org/1999/xhtml' style='display: table%3b white-space: break-spaces%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b width: 200px%3b'%3e%3cspan class='nodeLabel'%3e%3cp%3eDecision: Route more traffic to faster barista%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/svg%3e)
💻 Example Code Snippets
import numpy as np
# Example wait times in seconds
anna = np.array([25, 30, 28, 29, 27, 26, 31, 24], dtype=float)
ben = np.array([32, 35, 30, 29, 40, 33, 31, 34], dtype=float)
def describe(x):
mean = x.mean()
sd = x.std(ddof=1)
se = sd / np.sqrt(len(x))
return mean, sd, se
anna_mean, anna_sd, anna_se = describe(anna)
ben_mean, ben_sd, ben_se = describe(ben)
delta = anna_mean - ben_mean
se_delta = np.sqrt(anna_se**2 + ben_se**2)
z = delta / se_delta
print("Anna:", anna_mean, anna_sd, anna_se)
print("Ben :", ben_mean, ben_sd, ben_se)
print("delta:", delta)
print("SE_delta:", se_delta)
print("z-score:", z)
🎯 10. Conclusion
We’ve traveled from raw data to decision-making through a logical chain:
- Observe — collect messy, real-world data
- Summarize — compute means to find “typical” values
- Quantify spread — use standard deviation to measure consistency
- Estimate uncertainty — use standard error to understand how confident we are in our estimates
- Compare — calculate the difference between groups and its uncertainty
- Standardize — convert to a z-score for universal interpretation
- Decide — use hypothesis testing to make principled decisions with known error rates
The beauty of this framework is that it’s general-purpose. Whether you’re comparing baristas, A/B testing website designs, or evaluating treatment effects in medicine, the same logical progression applies.
Key insight: Statistics doesn’t give you certainty — it gives you a principled way to make decisions under uncertainty, with known and controlled error rates.
📚 What We Didn’t Cover
This guide focused on building intuition for the core concepts. Here are important topics for further study:
- Confidence intervals — instead of just testing “is there a difference?”, estimate the range of plausible values for the true difference
- t-tests vs z-tests — when sample sizes are small (< 30), the t-distribution accounts for additional uncertainty in estimating SD
- Effect size — statistical significance doesn’t tell you if a difference is practically meaningful (a 0.1 second difference might be “significant” but irrelevant)
- Multiple comparisons — testing many hypotheses inflates your false positive rate; corrections like Bonferroni or FDR control help
- Power analysis — how to determine sample size before collecting data to ensure you can detect meaningful effects
- Non-parametric tests — alternatives when your data doesn’t meet normality assumptions